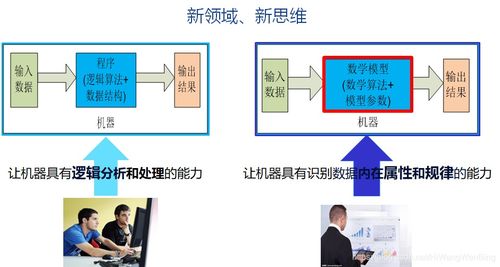
新一代大數(shù)據(jù)與人工智能基礎(chǔ)架構(gòu)技術(shù)的發(fā)展與趨勢 聚焦人工智能基礎(chǔ)軟件開發(fā)
隨著數(shù)據(jù)洪流的持續(xù)奔涌和智能算法的不斷突破,新一代大數(shù)據(jù)與人工智能(AI)基礎(chǔ)架構(gòu)技術(shù)正經(jīng)歷一場深刻的范式變革。這場變革的核心驅(qū)動(dòng)力,已從單純的算力堆疊和存儲(chǔ)擴(kuò)容,轉(zhuǎn)向了軟硬件協(xié)同、數(shù)據(jù)與智能一體化的系統(tǒng)級(jí)創(chuàng)新。其中,人工智能基礎(chǔ)軟件開發(fā)作為連接底層硬件、海量數(shù)據(jù)與上層智能應(yīng)用的“神經(jīng)中樞”,其發(fā)展水平直接決定了整個(gè)AI生態(tài)的效能、易用性和演進(jìn)速度。本文將探討這一領(lǐng)域的關(guān)鍵技術(shù)演進(jìn)與未來趨勢。
一、 技術(shù)演進(jìn):從專用工具到統(tǒng)一平臺(tái)
早期的大數(shù)據(jù)與AI基礎(chǔ)架構(gòu)往往是分離的,數(shù)據(jù)處理(如Hadoop/Spark)與模型訓(xùn)練/推理(如早期定制化CUDA程序)使用不同的棧,導(dǎo)致數(shù)據(jù)流轉(zhuǎn)效率低、開發(fā)運(yùn)維復(fù)雜。技術(shù)的發(fā)展呈現(xiàn)出顯著的融合與統(tǒng)一趨勢:
- 計(jì)算與存儲(chǔ)的融合架構(gòu):以數(shù)據(jù)湖倉一體(Lakehouse)為代表,打破了數(shù)據(jù)湖(靈活、低成本存儲(chǔ))與數(shù)據(jù)倉庫(高性能、強(qiáng)治理)的界限。通過像Apache Iceberg、Delta Lake、Apache Hudi這樣的開放表格式,以及Databricks、Snowflake等廠商的推動(dòng),實(shí)現(xiàn)了在統(tǒng)一存儲(chǔ)層上同時(shí)支持大數(shù)據(jù)處理(ETL、分析)和AI工作負(fù)載(特征工程、模型訓(xùn)練),減少了數(shù)據(jù)移動(dòng)和復(fù)制成本。
- 異構(gòu)計(jì)算的軟件抽象:面對(duì)CPU、GPU、NPU、FPGA等多種計(jì)算單元,基礎(chǔ)軟件的核心任務(wù)之一是提供高效的統(tǒng)一抽象。像PyTorch、TensorFlow等主流深度學(xué)習(xí)框架,通過其計(jì)算圖抽象和運(yùn)行時(shí),能夠?qū)⒏呒?jí)的模型描述映射到底層多樣的硬件上。更進(jìn)一步,編譯器技術(shù)(如MLIR多級(jí)中間表示、TVM)致力于實(shí)現(xiàn)“一次編寫,處處高效運(yùn)行”,自動(dòng)優(yōu)化模型在不同硬件后端上的性能。
- 工作流與資源管理的智能化:以Kubernetes為核心云原生技術(shù)棧成為AI基礎(chǔ)架構(gòu)的事實(shí)標(biāo)準(zhǔn)。在此基礎(chǔ)上,專為AI工作負(fù)載設(shè)計(jì)的平臺(tái)(如Kubeflow、MLflow)和批處理/工作流引擎(如Apache Airflow、Flyte)實(shí)現(xiàn)了從數(shù)據(jù)準(zhǔn)備、實(shí)驗(yàn)跟蹤、模型訓(xùn)練到部署監(jiān)控的全生命周期管理。資源調(diào)度器(如Kubernetes自身調(diào)度器、YARN或更專業(yè)的如Ray的分布式調(diào)度)正變得愈發(fā)智能,能夠感知AI任務(wù)的特點(diǎn)進(jìn)行動(dòng)態(tài)資源分配和彈性伸縮。
二、 人工智能基礎(chǔ)軟件開發(fā)的核心趨勢
AI基礎(chǔ)軟件的開發(fā)將圍繞以下幾個(gè)關(guān)鍵方向深化:
- “以數(shù)據(jù)為中心”的AI開發(fā)范式:Andrew Ng倡導(dǎo)的“以數(shù)據(jù)為中心”的AI正在重塑工具鏈。基礎(chǔ)軟件將更深度地集成數(shù)據(jù)質(zhì)量監(jiān)控、自動(dòng)標(biāo)注、版本控制(如DVC)、增強(qiáng)合成與持續(xù)的數(shù)據(jù)迭代循環(huán)工具。未來的AI平臺(tái)不僅僅是“模型工廠”,更是“數(shù)據(jù)精煉廠”。
- 大規(guī)模基礎(chǔ)模型的專用基礎(chǔ)設(shè)施:訓(xùn)練千億、萬億參數(shù)的大模型(LLMs)需要全新的軟件棧支持。這包括:
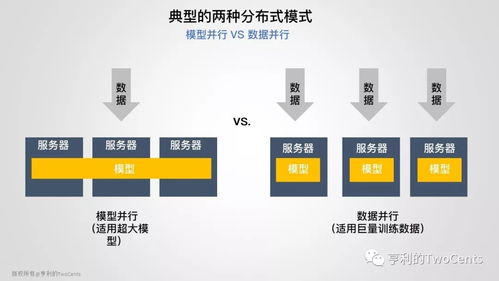
- 高效分布式訓(xùn)練框架:如DeepSpeed(零冗余優(yōu)化器、3D并行)、Megatron-LM(張量/流水線并行)及其集成方案,它們通過復(fù)雜的并行策略和內(nèi)存優(yōu)化,使大模型訓(xùn)練成為可能。
- 推理與服務(wù)優(yōu)化:針對(duì)大模型的高延遲、高內(nèi)存消耗,需要更高效的推理引擎(如vLLM、TGI)、量化壓縮工具(如GPTQ、AWQ)和動(dòng)態(tài)批處理、持續(xù)批處理等技術(shù),以降低服務(wù)成本。
- AI原生數(shù)據(jù)庫與向量數(shù)據(jù)棧的興起:隨著檢索增強(qiáng)生成(RAG)成為連接大模型與私有知識(shí)的關(guān)鍵,能夠高效處理向量嵌入的數(shù)據(jù)庫(如Pinecone、Weaviate、Milvus等向量數(shù)據(jù)庫)以及將傳統(tǒng)數(shù)據(jù)庫與向量搜索融合的“AI原生數(shù)據(jù)庫”(如PostgreSQL的pgvector擴(kuò)展、一些云廠商的新服務(wù))正成為基礎(chǔ)架構(gòu)的新要件。支持混合檢索(關(guān)鍵詞+向量)和復(fù)雜過濾的軟件層至關(guān)重要。
- 安全、可信與合規(guī)性內(nèi)置:隨著AI應(yīng)用的普及,模型安全(對(duì)抗攻擊)、數(shù)據(jù)隱私(聯(lián)邦學(xué)習(xí)、差分隱私)、可解釋性(XAI工具)和合規(guī)性(模型審計(jì)、數(shù)據(jù)溯源)不再是附加功能,而必須從基礎(chǔ)軟件層開始設(shè)計(jì)。開源項(xiàng)目如OpenXAI、TensorFlow Privacy等正推動(dòng)這一進(jìn)程。
- 低代碼/自動(dòng)化與開發(fā)者體驗(yàn):為了降低AI應(yīng)用開發(fā)門檻,基礎(chǔ)軟件正提供更高層次的抽象。自動(dòng)化機(jī)器學(xué)習(xí)(AutoML)工具、模型市場、預(yù)構(gòu)建的行業(yè)解決方案模板以及集成的可視化開發(fā)環(huán)境,讓領(lǐng)域?qū)<乙材軈⑴cAI構(gòu)建。為專業(yè)開發(fā)者提供無縫的本地-云協(xié)同開發(fā)、高效的調(diào)試與性能剖析工具,是提升生產(chǎn)力的關(guān)鍵。
三、 挑戰(zhàn)與展望
盡管前景廣闊,挑戰(zhàn)依然存在:軟硬件協(xié)同優(yōu)化的復(fù)雜度極高,生態(tài)碎片化(多種框架、芯片、云服務(wù))導(dǎo)致兼容性問題,系統(tǒng)的可觀測性和可調(diào)試性仍需加強(qiáng),以及成本控制始終是企業(yè)的核心關(guān)切。
新一代大數(shù)據(jù)與AI基礎(chǔ)架構(gòu)軟件將朝著更一體化(數(shù)據(jù)、訓(xùn)練、推理、管理無縫銜接)、更智能化(基礎(chǔ)設(shè)施具備自優(yōu)化、自愈能力)、更開放與標(biāo)準(zhǔn)化(避免廠商鎖定,促進(jìn)生態(tài)創(chuàng)新)的方向演進(jìn)。人工智能基礎(chǔ)軟件開發(fā),作為這場智能革命的基礎(chǔ)工程,其進(jìn)步將直接決定我們能在多大程度上釋放數(shù)據(jù)和算法的潛力,賦能千行百業(yè)的智能化轉(zhuǎn)型。
最新產(chǎn)品