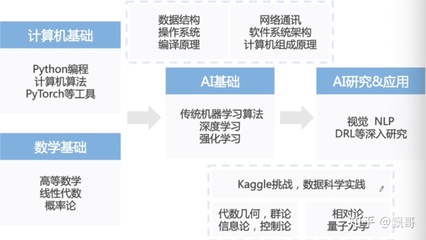
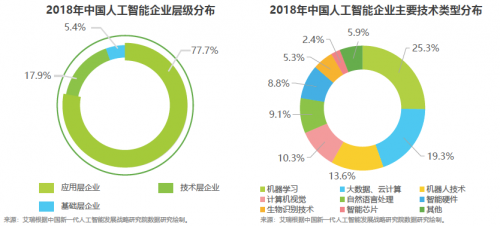
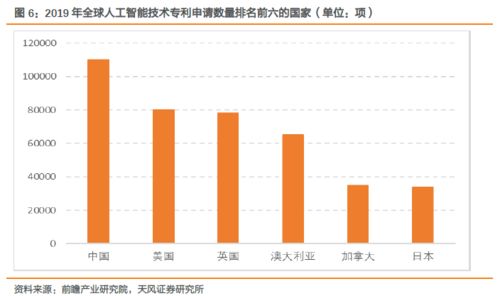
人工智能數(shù)學(xué)基礎(chǔ)(六) 常見數(shù)學(xué)函數(shù)與激活函數(shù)大全——構(gòu)建人工智能基礎(chǔ)軟件的基石
在人工智能(AI)的基礎(chǔ)開發(fā)中,數(shù)學(xué)是貫穿始終的靈魂,而各類數(shù)學(xué)函數(shù),特別是神經(jīng)網(wǎng)絡(luò)中的激活函數(shù),則是構(gòu)建智能模型的磚瓦。本文將系統(tǒng)梳理人工智能領(lǐng)域所需的核心數(shù)學(xué)函數(shù),并重點匯編一份詳盡的激活函數(shù)大全,為AI基礎(chǔ)軟件開發(fā)提供理論支撐和實踐指引。
一、人工智能中的基礎(chǔ)數(shù)學(xué)函數(shù)
在AI模型(尤其是深度學(xué)習(xí))的構(gòu)建、訓(xùn)練和優(yōu)化過程中,以下幾類數(shù)學(xué)函數(shù)扮演著至關(guān)重要的角色:
- 線性函數(shù):形式為
y = Wx + b。這是神經(jīng)網(wǎng)絡(luò)每一層最基礎(chǔ)的變換,負(fù)責(zé)對輸入數(shù)據(jù)進(jìn)行加權(quán)求和。權(quán)重W和偏置b是模型需要學(xué)習(xí)的關(guān)鍵參數(shù)。
- 指數(shù)與對數(shù)函數(shù):
- 指數(shù)函數(shù)(如 exp(x)):在Softmax函數(shù)、某些激活函數(shù)(如ELU)及概率模型中廣泛應(yīng)用。
- 對數(shù)函數(shù)(如 log(x)):是交叉熵?fù)p失函數(shù)的核心組成部分,用于衡量概率分布之間的差異,是分類任務(wù)中最常用的損失函數(shù)之一。
- 三角函數(shù)(如 sin, cos):在位置編碼(如Transformer模型中的正弦余弦編碼)、信號處理以及某些特定結(jié)構(gòu)的網(wǎng)絡(luò)中有重要應(yīng)用。
- 統(tǒng)計與概率函數(shù):
- Softmax函數(shù):將一組實數(shù)(通常是邏輯回歸值)轉(zhuǎn)換為概率分布,是多分類問題的標(biāo)準(zhǔn)輸出層函數(shù)。
- Sigmoid函數(shù):本質(zhì)上也是一個概率函數(shù),將輸入映射到(0,1)區(qū)間,常用于二分類輸出層或表示概率。
- 高斯(正態(tài))分布函數(shù):在變分自編碼器(VAE)、高斯過程等概率生成模型中至關(guān)重要。
二、神經(jīng)網(wǎng)絡(luò)激活函數(shù)大全
激活函數(shù)是神經(jīng)網(wǎng)絡(luò)的“非線性引擎”,它決定了神經(jīng)元是否被激活以及如何將輸入信號映射到輸出。沒有它,神經(jīng)網(wǎng)絡(luò)將退化為線性模型,無法學(xué)習(xí)復(fù)雜模式。以下是對常見激活函數(shù)的系統(tǒng)性
(一)飽和激活函數(shù)(早期常用)
- Sigmoid (Logistic函數(shù))
- 公式:
σ(x) = 1 / (1 + exp(-x))
- 值域:(0, 1)
- 優(yōu)點:輸出平滑,易于解釋(可作為概率)。
- 缺點:容易導(dǎo)致梯度消失(在兩端飽和區(qū)梯度接近0);輸出不以0為中心,影響梯度下降效率;計算涉及指數(shù),較慢。
- 主要應(yīng)用:二分類輸出層。
- Tanh (雙曲正切函數(shù))
- 公式:
tanh(x) = (exp(x) - exp(-x)) / (exp(x) + exp(-x))
- 值域:(-1, 1)
- 優(yōu)點:輸出以0為中心,收斂速度通常比Sigmoid快。
- 缺點:同樣存在梯度消失問題。
- 主要應(yīng)用:循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)的隱藏層。
(二)非飽和激活函數(shù)(現(xiàn)代主流)
- ReLU (Rectified Linear Unit,整流線性單元)
- 公式:
f(x) = max(0, x)
- 優(yōu)點:計算極其高效,解決了梯度消失問題(在正區(qū)間);收斂速度遠(yuǎn)快于Sigmoid/Tanh。
- 缺點:“Dead ReLU”問題(負(fù)半軸梯度恒為0,導(dǎo)致部分神經(jīng)元永久失活);輸出不以0為中心。
- 應(yīng)用:最常用,是絕大多數(shù)卷積神經(jīng)網(wǎng)絡(luò)(CNN)和全連接層的默認(rèn)選擇。
- Leaky ReLU 及其變種
- 公式:
f(x) = max(αx, x),其中α是一個小的正數(shù)(如0.01)。
- 優(yōu)點:解決了“Dead ReLU”問題,為負(fù)輸入提供了一個小的梯度α。
- 變種:Parametric ReLU (PReLU),將α作為可學(xué)習(xí)參數(shù);Randomized ReLU (RReLU),在訓(xùn)練時α隨機采樣。
- ELU (Exponential Linear Unit,指數(shù)線性單元)
- 公式:
f(x) = x (if x > 0) else α(exp(x)-1)
- 優(yōu)點:輸出均值接近0,收斂更快;對噪聲更具魯棒性;解決了Dead ReLU問題。
- 缺點:計算涉及指數(shù),稍慢于ReLU。
- Swish 函數(shù) (由Google發(fā)現(xiàn))
- 公式:
f(x) = x * sigmoid(βx),β可以是常數(shù)或可學(xué)習(xí)參數(shù)。
- 特點:平滑、非單調(diào)。在實踐中,尤其在深層模型上,有時表現(xiàn)優(yōu)于ReLU。
- GELU (Gaussian Error Linear Unit,高斯誤差線性單元)
- 公式:
f(x) = x <em> Φ(x),其中Φ(x)是標(biāo)準(zhǔn)正態(tài)分布的累積分布函數(shù)。常用近似:0.5x </em> (1 + tanh[√(2/π)(x + 0.044715x^3)])
- 特點:在Transformer模型(如BERT, GPT)中廣泛采用,因其設(shè)計考慮了隨機正則化的效果,性能優(yōu)異。
(三)輸出層專用函數(shù)
- Softmax:如前所述,用于多分類,將輸出歸一化為概率分布。
- Linear (恒等函數(shù)):用于回歸任務(wù),輸出層直接輸出加權(quán)和。
三、在AI基礎(chǔ)軟件開發(fā)中的實踐指引
對于AI基礎(chǔ)軟件(如深度學(xué)習(xí)框架)的開發(fā)者和使用者,理解這些函數(shù)至關(guān)重要:
- 框架設(shè)計:優(yōu)秀的AI框架(如PyTorch, TensorFlow)會在其核心庫(如
torch.nn.functional,tf.nn)中高效實現(xiàn)所有這些函數(shù),并提供自動求導(dǎo)支持。 - 模型構(gòu)建:開發(fā)者應(yīng)根據(jù)任務(wù)類型選擇激活函數(shù)。一般原則:
- 隱藏層:優(yōu)先使用 ReLU 及其變種(Leaky ReLU, GELU),它們是當(dāng)前的最佳實踐起點。
- RNN隱藏層:可考慮 Tanh 或 ReLU。
- 輸出層:二分類用Sigmoid,多分類用Softmax,回歸用Linear。
- 性能調(diào)優(yōu):當(dāng)使用ReLU遇到神經(jīng)元“死亡”時,可嘗試Leaky ReLU或ELU。在非常深的網(wǎng)絡(luò)或Transformer中,GELU或Swish可能帶來增益。
- 自定義開發(fā):研究人員有時需要為特定任務(wù)設(shè)計新的激活函數(shù)。基礎(chǔ)軟件應(yīng)提供易于擴展的接口。
###
數(shù)學(xué)函數(shù)與激活函數(shù)是連接人工智能抽象理論與具體軟件實現(xiàn)的橋梁。從基礎(chǔ)的線性變換到復(fù)雜的非線性激活,它們共同賦予了神經(jīng)網(wǎng)絡(luò)強大的表征學(xué)習(xí)能力。掌握這份“函數(shù)大全”并理解其背后的原理,是進(jìn)行高效、創(chuàng)新的AI基礎(chǔ)軟件開發(fā)與應(yīng)用的必備條件。隨著AI研究的深入,未來必將涌現(xiàn)出更多性能卓越、生物學(xué)可解釋性更強的新型函數(shù),持續(xù)推動著整個領(lǐng)域向前發(fā)展。
最新產(chǎn)品